Binary Exploitation Series (2): Bug Classes
This post gives a brief overview of some bug classes, but it will not cover everything in detail. I’ll provide some additional resources for bug classes which I’m not covering in this series.
How to find vulnerabilities?
There are two essential ways to identify vulnerabilities in software. Fuzzing and static/dynamic code analysis. While fuzzing is a more “aggressive” way of spamming different test cases against the program, an audit is a more focused task. In CTF’s I prefer the manual analysis of the target because most of the time bugs are somewhat hidden and you can find a magic value easier with a disassembler instead of random inputs as test cases.
Bug Classes
There are many different possible attack vectors in today’s native binaries. I won’t cover all of them but to give you an idea, here is a small list:
- Stack Buffer Overflows
- Heap Buffer Overflows
- Format String Attacks
- Use After Free (UAF)
- Information Leaks (e.g. Format String Attacks, Off by One)
- Logic Flaws
- …
Stack Based Buffer Overflows
Stack-based buffer overflows are (often) a simple way to get code execution on the target. The best way to explain such an attack is with an example, like always. ;-)
The following function is treated as 32-bit (architecture).
void vuln_function(char *input) {
char local_buffer[32];
strcpy(local_buffer, input);
}
The main idea of a buffer overflow is that we can write out of bounds of a variable e.g. an array. This means, that we can fill a buffer on the stack (here 32 bytes) with more data than it can store.
In the following figure, we see the stack of the above function. ESP is the stack pointer and EBP is the base pointer.
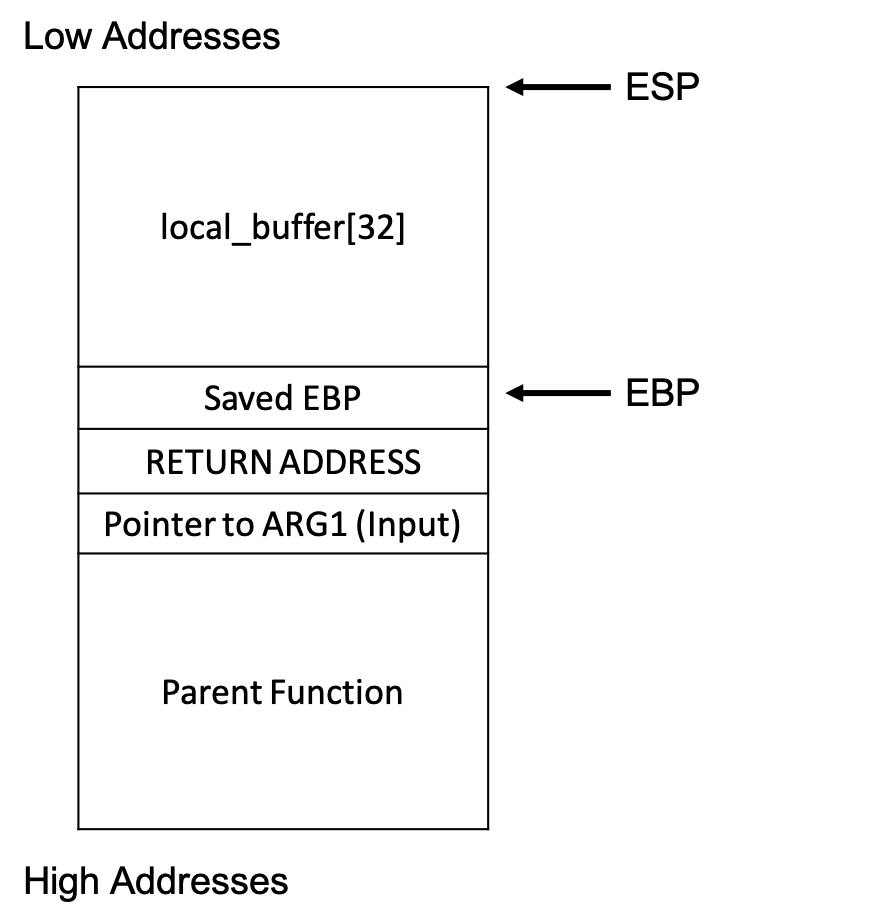
If we have “AAAA\0” as an input, the stack is as follows:

If we put more data than the buffer can hold (e.g. "A"*32 + "B"*4 + "C"*4) we can overwrite the saved base pointer and the return address of the function.

As soon as we return from the function (ret) the C’s will be used as the next instruction pointer and we get a SEGFAULT. Therefore, we know that something is corrupted and we may have control of the execution flow (without protections enabled, see later chapters). Important to note, that you could overwrite other variables too. That means, that perhaps you do not need to overwrite the return address because overwriting a specific variable on the stack is enough to achieve your goal.
Heap Exploitation
Heap-based buffer overflows are in general the same as stack-based buffer overflows, but you are overflowing a buffer on the heap. Therefore, you cannot directly overwrite e.g. a return address but rather have to figure out how the application works. Then you can manipulate other variables like pointer to strings (you’ll maybe get a write/read primitive), heap metadata and even function pointers on the heap (e.g. a struct which has pointers to other functions) to get control over the execution flow.
I can recommend How2Heap which covers a lot of heap exploitation techniques.
Format String Attacks
Format strings can be used in a few functions like printf.
char *name = "MyName";
int age = 34;
printf("%s is %d years old.", name, age);
In this example, we have a format string (arg1) and we replace the %s with the content of the second argument name and the %d formatter with the value of age. The vulnerability occurs if we let the user manipulate or even set the format string.
For example:
char buf[30];
int count = read(0, buf, 29);
buf[count] = '\0';
printf(buf); // buffer could contain formatter -> %x %s %c ...
When we put the string %x%x%x as a buffer for printf we can leak data of the stack. We can also read arbitrary addresses and also write to arbitrary addresses in memory.
You can read more about this type of exploitation at Format String Attacks syr.edu or watch a video of LiveOverflow
Look out for functions like: printf, sprintf, vprintf, vsprintf, ….
That’s it for today. Next time, we’ll finally exploit our first target!
See you soon.